 During Objective Peach, Lt. Col. Ernest "Rock" Marcone, a battalion commander with the 69th Armor of the Third Infantry Division, was starved for information about Iraqi troop movements and as he said in the Technology Review article, "I would argue that I was the intelligence-gathering device for my higher headquarters."
During Objective Peach, Lt. Col. Ernest "Rock" Marcone, a battalion commander with the 69th Armor of the Third Infantry Division, was starved for information about Iraqi troop movements and as he said in the Technology Review article, "I would argue that I was the intelligence-gathering device for my higher headquarters."
10.30.2004
Horizontal Leadership: Bridging the Information Gap
During Objective Peach, Lt. Col. Ernest "Rock" Marcone, a battalion commander with the 69th Armor of the Third Infantry Division, was starved for information about Iraqi troop movements and as he said in the Technology Review article, "I would argue that I was the intelligence-gathering device for my higher headquarters."
10.28.2004
'Knowledge discovery' could speed creation of new products
John Anderton: "I need your help. You contain information. I need to know how to get at it."
In the recent science-fiction thriller "Minority Report," Tom Cruise plays Detective John Anderton who solves future crimes by being immersed in a "data cave," where he rapidly accesses all the relevant information about the identity, location and associates of the potential victim. A team at PurdueUniversity is currently developing a similar "data-rich" environment for scientific discovery that uses high-performance computing and artificial intelligence software to display information and interact with researchers in the language of their specific disciplines.
"If you were a chemist, you could walk right up to this display and move molecules and atoms around to see how the changes would affect a formulation or a material's properties," said James Caruthers, a professor of chemical engineering at Purdue. The method represents a fundamental shift from more conventional techniques in computer-aided scientific discovery.
A team at PurdueUniversity is currently developing a similar "data-rich" environment for scientific discovery that uses high-performance computing and artificial intelligence software to display information and interact with researchers in the language of their specific disciplines.
"If you were a chemist, you could walk right up to this display and move molecules and atoms around to see how the changes would affect a formulation or a material's properties," said James Caruthers, a professor of chemical engineering at Purdue. The method represents a fundamental shift from more conventional techniques in computer-aided scientific discovery.
 "Most current approaches to computer-aided discovery center on mining data in a process that assumes there is a nugget of gold that needs to be found in a sea of irrelevant information," Caruthers said. "This data-mining approach is appropriate for some scientific discovery problems, but scientific understanding often proceeds through a different method, a 'knowledge discovery' approach.
"Instead of mining for a nugget of gold, knowledge discovery is more like sifting through a warehouse filled with small gears, levers, etc., none of which is particularly valuable by itself. After appropriate assembly, however, a Rolex watch emerges from the disparate parts."
A team of researchers at Purdue led by Caruthers is developing a computer environment that allows experts to talk naturally in their specific scientific language. That way, the researchers don't have to deal with computerese and can take full advantage of the most advanced visualization capabilities to become more engaged in the scientific discovery process, Caruthers said.
Such a system could become crucial for enabling scientists to deal with the recent explosion of data now available to them. The source of this flood of data is "high-throughput" experimentation, in which hundreds or thousands of experiments are conducted simultaneously in tiny vessels that are sometimes as small as a few human hairs. Having so much information presents a challenge: it is difficult for researchers to find what they are looking for within this huge sea of data.
"Most current approaches to computer-aided discovery center on mining data in a process that assumes there is a nugget of gold that needs to be found in a sea of irrelevant information," Caruthers said. "This data-mining approach is appropriate for some scientific discovery problems, but scientific understanding often proceeds through a different method, a 'knowledge discovery' approach.
"Instead of mining for a nugget of gold, knowledge discovery is more like sifting through a warehouse filled with small gears, levers, etc., none of which is particularly valuable by itself. After appropriate assembly, however, a Rolex watch emerges from the disparate parts."
A team of researchers at Purdue led by Caruthers is developing a computer environment that allows experts to talk naturally in their specific scientific language. That way, the researchers don't have to deal with computerese and can take full advantage of the most advanced visualization capabilities to become more engaged in the scientific discovery process, Caruthers said.
Such a system could become crucial for enabling scientists to deal with the recent explosion of data now available to them. The source of this flood of data is "high-throughput" experimentation, in which hundreds or thousands of experiments are conducted simultaneously in tiny vessels that are sometimes as small as a few human hairs. Having so much information presents a challenge: it is difficult for researchers to find what they are looking for within this huge sea of data.
Drowning in data, yet starved of information - Ruth Stanat in The Intelligent Organization
"You run the risk of drowning in data," said W. Nicholas Delgass, a Purdue professor of chemical engineering. "What you really want is knowledge, not data." Purdue researchers believe they have a solution to the problem. They are developing a method to extract knowledge from data, promising to speed up the process of discovery in many areas of research, including work aimed at creating new drugs, fuel additives, catalysts and rubber compounds. The method, called discovery informatics, enables researchers to test new theories on the fly and literally see how well their concepts might work in real time via a three-dimensional display, said Venkat Venkatasubramanian, another professor of chemical engineering working to develop the new system. Discovery informatics depends on a two-part repeating cycle made up of a "forward model" and an "inverse process" and two types of artificial intelligence software: hybrid neural networks and genetic algorithms. The forward model combines fundamental knowledge and rules of thumb with neural networks � software that mimics how the human brain thinks � to tell researchers how a particular material will perform. The inverse process is just the opposite: Researchers enter the properties they are looking for, and the system gives them a molecular structure or formulation that will likely have those properties. The inverse process cannot begin until the forward model is completed because the former depends on information in the model.Anxiety good for memory recall, bad for complex problem solving
Students, keep this in mind before that next major exam: Pre-test jitters make it easier to recall memorized facts, but that stress also makes it tough to solve more complex problems. Researchers at Ohio State University gave a battery of simple cognitive tests to 19 first-year medical students one to two days before a regular classroom exam -- a period when they would be highly stressed. Students were also given a similar battery of tests a week after the exam, when things were less hectic.
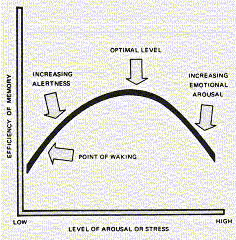 This is closely related to the Yerkes-Dodson law -- A certain amount of arousal (in this case anxiety) can be a motivator toward change (with change in this case being learning). But too much or too little anxiety or arousal works against the learner. You want some mid-level of arousal to provide the motivation to change (learn). This is because too little arousal has an inert affect on the learner, while too much has a hyper affect. There are optimal levels of arousal for each task to be learned. The optimal level of arousal is:
This is closely related to the Yerkes-Dodson law -- A certain amount of arousal (in this case anxiety) can be a motivator toward change (with change in this case being learning). But too much or too little anxiety or arousal works against the learner. You want some mid-level of arousal to provide the motivation to change (learn). This is because too little arousal has an inert affect on the learner, while too much has a hyper affect. There are optimal levels of arousal for each task to be learned. The optimal level of arousal is:
This is closely related to the Yerkes-Dodson law -- A certain amount of arousal (in this case anxiety) can be a motivator toward change (with change in this case being learning). But too much or too little anxiety or arousal works against the learner. You want some mid-level of arousal to provide the motivation to change (learn). This is because too little arousal has an inert affect on the learner, while too much has a hyper affect. There are optimal levels of arousal for each task to be learned. The optimal level of arousal is:
- higher for tasks requiring endurance and persistence
- lower for more difficult or intellectually (cognitive) tasks
10.25.2004
Somewhere in Florida, 25,000 disembodied rat neurons are thinking about flying an F-22
 Researchers at the University of Florida have created a neural network made up of 25,000 disembodied rat neurons and hooked it up to a flight simulator on a desktop computer. The neurons, which are growing on top of a multi-electrode array (MEA), are fed information about the simulated F-22's horizontal and vertical movements by stimulating the electrodes, causing them to fire in patterns that are then used to control the aircraft. "It's as if the neurons control the stick in the aircraft, they can move it back and forth and left and right," says UF professor Thomas DeMarse. The cellsrapidly begin to re-establish connectivity within a few hours of being placed on the MEA. These arrays can both record and stimulate the action potentials of neurons near each electrode (electrical signals between neurons) as they communicate within these dense networks.
Researchers at the University of Florida have created a neural network made up of 25,000 disembodied rat neurons and hooked it up to a flight simulator on a desktop computer. The neurons, which are growing on top of a multi-electrode array (MEA), are fed information about the simulated F-22's horizontal and vertical movements by stimulating the electrodes, causing them to fire in patterns that are then used to control the aircraft. "It's as if the neurons control the stick in the aircraft, they can move it back and forth and left and right," says UF professor Thomas DeMarse. The cellsrapidly begin to re-establish connectivity within a few hours of being placed on the MEA. These arrays can both record and stimulate the action potentials of neurons near each electrode (electrical signals between neurons) as they communicate within these dense networks.
CLO Dashboard Puts Learning Executives in the Driver's Seat
CLO Dashboard, a strategic reporting and decision-making system for chief learning officers, learning managers and executives, has is now in Beta production by Zeroed-In Technologies announces its flagship product. CLO Dashboard is built on a corporate performance management framework and is tailored to the learning industry with predefined Key Performance Indicators (KPI) including learning efficiency, learning effectiveness, compliance and readiness.
 The main page of the dashboard shows a series of odometer-style gauges for each indicator and its supported goal. Executives can drill down to reveal underlying objectives, key measures, historical and projected trends, and comparative industry benchmarks. The system also keeps track of strategic learning projects by monitoring timelines, resources, and key milestones.
A recent USA TODAY Gallup Poll of U.S.executives cited more than 60 percent of their time is spent on strategic thinking and planning, and the planning of measurement and monitoring activities. "Chief learning officers must continually show the value of learning to the enterprise. Planning and measuring their strategy are crucial but time-consuming," says Chris Moore, president of Zeroed-In. "CLO Dashboard accelerates that effort and gives learning executives a single place to monitor all key learning indicators, and the business intelligence they need to make timely decisions to support or counteract trends."
CLO Dashboard is 100% web-based and interfaces with other systems using Extensible Markup Language (XML) and Web Services. The system will provide built-in connectors to leading learning platforms including THINQ, Pathlore, EEDO, and Questionmark.
The main page of the dashboard shows a series of odometer-style gauges for each indicator and its supported goal. Executives can drill down to reveal underlying objectives, key measures, historical and projected trends, and comparative industry benchmarks. The system also keeps track of strategic learning projects by monitoring timelines, resources, and key milestones.
A recent USA TODAY Gallup Poll of U.S.executives cited more than 60 percent of their time is spent on strategic thinking and planning, and the planning of measurement and monitoring activities. "Chief learning officers must continually show the value of learning to the enterprise. Planning and measuring their strategy are crucial but time-consuming," says Chris Moore, president of Zeroed-In. "CLO Dashboard accelerates that effort and gives learning executives a single place to monitor all key learning indicators, and the business intelligence they need to make timely decisions to support or counteract trends."
CLO Dashboard is 100% web-based and interfaces with other systems using Extensible Markup Language (XML) and Web Services. The system will provide built-in connectors to leading learning platforms including THINQ, Pathlore, EEDO, and Questionmark.
The main page of the dashboard shows a series of odometer-style gauges for each indicator and its supported goal. Executives can drill down to reveal underlying objectives, key measures, historical and projected trends, and comparative industry benchmarks. The system also keeps track of strategic learning projects by monitoring timelines, resources, and key milestones.
A recent USA TODAY Gallup Poll of U.S.executives cited more than 60 percent of their time is spent on strategic thinking and planning, and the planning of measurement and monitoring activities. "Chief learning officers must continually show the value of learning to the enterprise. Planning and measuring their strategy are crucial but time-consuming," says Chris Moore, president of Zeroed-In. "CLO Dashboard accelerates that effort and gives learning executives a single place to monitor all key learning indicators, and the business intelligence they need to make timely decisions to support or counteract trends."
CLO Dashboard is 100% web-based and interfaces with other systems using Extensible Markup Language (XML) and Web Services. The system will provide built-in connectors to leading learning platforms including THINQ, Pathlore, EEDO, and Questionmark.
10.24.2004
Workforce Planning in Complex Organizations
In 2000, the Acquisition Workforce 2005 Task Force of the Office of the Secretary of Defense (OSD) called for the development and implementation of needs-based human resource performance plans for Department of Defense (DoD) civilian acquisition workforces. The greater need for workforce planning is expected to arise from an unusually heavy workforce turnover, itself due to a large number of expected retirements among older employees in a workforce that has not hired younger new workers in recent years, as well as from an expected transformation in acquisition products and methods in coming years.
Workforce planning helps to ensure that an organization has the right mix of education, experience, etc. of personnel to advance its functional and organizational objectives. To succeed, workforce planning should answer questions regarding desired workforce characteristics now and in the future, and how organizational practices are helping maintain or develop these characteristics. Among elements needed to make workforce planning successful are active executive and line manager participation, accurate and relevant data, and sophisticated workload and inventory projection models.

Bricks & Clicks
 Investors who bought the bubble-era hype about "anywhere, anytime" learning that it would quickly put an end to education as we know it lost tens of millions in the dot-com crash. A key reason -- they wildly underestimated the cost and difficulty of delivering quality E-courses. Yet now that so many hard lessons have been learned, a more subtle but perhaps just as significant shift is well underway. Even as enrollment in online distance programs nears 1 million and grows by more than 20 percent a year, according to Boston research firm Eduventures, the much bigger audience turns out to be right in the classroom building. As colleges and high schools embrace "bricks and clicks" instruction some of it in class, some of it on the Web many experts see a future in which there's no longer a divide but a spectrum: Some classes will never hold a face-to-face meeting, some will meet once a week or once a month and interact electronically the rest of the time, and some will carry on the old-fashioned way. "E-learning is going to disappear as a [distinct] concept," predicts Matthew Pittinsky, chairman of Blackboard Inc., whose course-management and other software served 15,000 students in 1998 and six years later reaches 12 million in 50 countries.
Allison Rossett: "E-Learning gurus Elliot Maisie and Brandon Hall recognize the many options and encourages combined systems, which they call 'brick and click,' or 'blended.'"
She continues, "But what would those combinations look like? How much brick and how much click? How do performances and need data transfer into those decisions? Will the issue be brick-ness verses click-ness or the strategies used within the particular delivery systems, a point of view that harkens back to Clark's (1983) work on strategies and media. His strong case focused attention on learning strategies over any particular medium." -- from Allison Rossett and Kendra Sheldon (2001). Beyond the Podium (2001) pp. 281-282.
Investors who bought the bubble-era hype about "anywhere, anytime" learning that it would quickly put an end to education as we know it lost tens of millions in the dot-com crash. A key reason -- they wildly underestimated the cost and difficulty of delivering quality E-courses. Yet now that so many hard lessons have been learned, a more subtle but perhaps just as significant shift is well underway. Even as enrollment in online distance programs nears 1 million and grows by more than 20 percent a year, according to Boston research firm Eduventures, the much bigger audience turns out to be right in the classroom building. As colleges and high schools embrace "bricks and clicks" instruction some of it in class, some of it on the Web many experts see a future in which there's no longer a divide but a spectrum: Some classes will never hold a face-to-face meeting, some will meet once a week or once a month and interact electronically the rest of the time, and some will carry on the old-fashioned way. "E-learning is going to disappear as a [distinct] concept," predicts Matthew Pittinsky, chairman of Blackboard Inc., whose course-management and other software served 15,000 students in 1998 and six years later reaches 12 million in 50 countries.
Allison Rossett: "E-Learning gurus Elliot Maisie and Brandon Hall recognize the many options and encourages combined systems, which they call 'brick and click,' or 'blended.'"
She continues, "But what would those combinations look like? How much brick and how much click? How do performances and need data transfer into those decisions? Will the issue be brick-ness verses click-ness or the strategies used within the particular delivery systems, a point of view that harkens back to Clark's (1983) work on strategies and media. His strong case focused attention on learning strategies over any particular medium." -- from Allison Rossett and Kendra Sheldon (2001). Beyond the Podium (2001) pp. 281-282.
Subscribe to:
Posts (Atom)